


推荐产品
联系我们
- 联系人 : 张经理
- 手机 : 13906191784
- 电话 : 0510-83587010
- 网址 : www.tianhuiyouxiji.com
- 地址 : 无锡市玉祁工业园
bob和博鱼是不是一家/材料库
巨头王炸不断硬核解读芯片技术路线
最近整个半导体行业实在风起云涌, IBM 推出了 2nm 的芯片 ,苹果春季发布会上搭载 M1 的 iPad Pro 再度炸场、四月中旬 ARM 推出了新一代的 ARMv9 、 英特尔也拿出了最的至强三代 Ice Lake-SP ,四月初英伟达推出号称能将 AI 算力提升 10 倍的 CPU 芯片 Grace ,年初 AMD 的 ZEN3 系列芯片也正式亮相,接下来笔者就带大家解读一下半导体的巨头们到底打的什么技术牌。
我们在聊龙芯的时候,有热心的读者就说希望把 CISC 的 X86 指令与龙芯 LoongArch 作对比,这次我们就来详细聊一下这方面的话题,目前 RISC 阵营的最强处理器苹果 M1 其之所以性能如此劲爆,8 路的译码器提供了强大的助力作用。我们根据代码来看一下这方面的情况。
但是 X86 这样的做法也有着反噬,我们大家可以把 push move 这些指令左边的数字简单为机器指令,能够正常的看到 X86 为代表的 CISC 是不定长的,而龙芯 LA64 和 ARM 是定长的,对比 CISC 的架构来看现代的 RISC 芯片一般都是以流水线机制运行。像 AMD 最新的 ZEN3 系列 CPU,也只配备了 4 个译码器,因为不定长所以 X86 的 CPU 必须对可能的编码开始位置一起进行译码,并处理很多的错误,我们在前文也介绍过计算机的运行就怕分支预测,一旦预测不准,就会在流水线上产生气泡,这所带来的惩罚效应惊人。
多路译码的重点是以 ARM 为代表的 RISC 指令集绝大多数都是定长的,这也是苹果 M1 能有 8 路译码器的原因,当然从结果上看,ZEN3 还是要比 M1 略强一点的,但是 ZEN3 的译码器主频是 5Ghz,而 M1 只有 3.2Ghz,个人觉得苹果之所以没有将 M1 的主频的很高还是出于控制能耗原因,而不代表他不能这么做。因此从这个方面来看未来在桌面领域 X86 为代表的 CISC 恐怕前景不妙。
说起安全计算这项技术,他的历史已经很久远了,这样的一个问题起源于百万富翁问题,假如两个百万富翁街头邂逅,他们都想炫一下富,比比谁更有钱,但是出于隐私,都不想让对方清楚自己到底拥有多少财富,如何在不借助第三方的情况下,让他们了解彼此之间到底谁更有钱?针对百万富翁问题上世纪80年代,清华大学的姚期智院士提出了解决方案,并因此获取了图灵奖,从理论层面证明了多方可信计算问题的可行性。
其实英特尔安全计算指令集的 SGX 技术早在几年前就已经实现了,这是一种从硬件角度打消用户疑虑的技术,安全计算指令集实际是给计算机加了一个安全密室,即使拥有最高权限的特权管理员也不能进入安全密室,更无法在安全密室前布放监控。安全密室与外界的一切交互全部要经过加密并进行完整性校验。
但当时 SGX 能创建的内存空间只有 128M,而目前的 AI 机器学习模型动辙要上百 M,大的甚至要几十上百个 G,当时的 SGX 根本放不下这样的模型,无法在多方安全计算中使用。不过这次英特尔至强三代的 Ice Lake-SP 和马上就要来临的 ARM V9 中都能支持 TB 级的安全空间,可见安全计算也是巨头们的一个重要发展趋势。但在实践层面多方安全计算依然困扰业界,如果两个富翁只比一次那么一切好说,但是如果有恶意假扮者,不断和同一个富翁A比富,那么富翁A的信息泄漏是迟早的事。
笔者看到目前比如像蓝象智联的 GAIA CUBE 等联邦计算平台,就有将区块链技术与硬件安全计算结合的方案,避免同一用户的信息被不断的碰撞学习,保障数据安全性,做到最终数据可用不可见,打破数据孤岛。软硬结合实现安全联邦计算可能是一个今后业界发展的重要趋势之一。
我们看到最近亮相的英特尔的至强三代 Ice Lake-SP 和安谋的 ARM v9 以及英伟达的首款 CPU 处理器 Grace,都把宝押在了 AI 算力方面。不过显然英伟达选择的技术路线与英特尔以及 ARM 不同,虽然 Grace 是基于 ARM 的,但是黄教主的方案是打通内存与显存之间的数据交换瓶颈。
正如我们刚才所说 ARM 等 RISC 处理器在指令预测等方面同天然比 X86 更有优势,能耗也比 X86 更低。当然这些都是 ARM 相对于 X86 的传统优势,本次 Grace 最大的创新点在于把 CPU 与 GPU 之间的通信速度提升了近 10 倍。根据黄仁勋的说法,“这是一万名工程人员历经几年的研发成果,旨在满足当前世界最先进应用程序的计算需求,其具备的计算性能和吞吐速率是以往任何架构所不能够比拟的。”
CPU 和 GPU 的通信速度的重要性,也可以用苹果 M1 的例子来加以说明,我们大家都知道苹果 M1 显卡与内存加在一起只有 16 个 G,对比上一代 Mac PRO 内存 128G,光是显存都有 16G,不过搭载 M1 的入门版 Mac 在进行图像处理等需要 CPU 与 GPU 进行协同的运算任务时,至少比上一代顶配的 Mac 性能高出近一倍。其中的秘决就是将内存与显卡进行统一管理,从而大幅度的提升了 CPU 与 GPU 的通信效率。Grace 体系中 GPU 核心与 CPU 核心之间的通信不需要 CPU 的调度,也不需要占用数据总线的带宽,之前 CPU 必须将数据从其内存的区域复制到 GPU 使用的区域,而在 Grace 的加持下,CPU 只需要告诉 GPU 在内存的某位置有 30MB 的向量数据,然后就可以去做其它事了,GPU 则能够最终靠 Grace 复制通道迅速开始计算任务。
同时我们把目光转移到 Grace 发布上,英伟达还拿出了很多软件产品,比如 Transformers 训练框架 NVIDIA Megatron、Morpheus 数据中心安全平台、新一代人工智能对话机器人 NVIDIA Jarvis、推荐系统是 NVIDIA Merlin、隐私保护加强的 AI 辅助套件 NVIDIA TAO,今后软硬结合的一体化计算框架可能也会成为趋势。
在英伟达发起了收购 ARM 的要约之后,必然预示云计算市场将是各大巨头重要的争夺方向。
在云计算这种多租户的场景下,可能有很多用户依靠虚拟化技术使用同一 CPU 工作,这就要求不同用户使用的内存要严格隔离,因此苹果 M1 以及英伟达 Grace 将内存与显存混用打通 CPU 与 GPU 的方式不利于虚拟化的加速。基于上述原因,目前英伟达和苹果 M1 的算力提升还暂时影响不到云计算市场,目前英特尔在云计算方面还是占据不少优势。据笔者了解到的情况看,在最新的至强三代 Ice Lake-SP 系列中中有两款专为云计算虚拟机和容器来优化的型号,其中
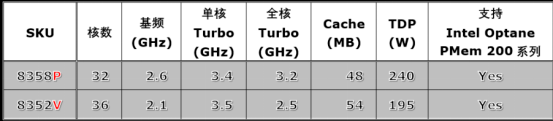
代表为 SaaS 优化,针对高密度、低功耗容器环境,提高编排效率。阿里云是目前使用至强三代比较多的国内云厂商之一。阿里云与英特尔同步发布的第七代 ECS 云产品,搭载的就是这款 Ice Lack,如果笔者所料不错的话,其小型号就应该是我们刚刚提到的 8358P 系列的芯片。
以上就是笔者对于最近半导体行业最新进展的一些解读,欢迎各位一起交流探讨。
☞ 微软董事会:比尔·盖茨应当离开;字节跳动回应“实习生遭遇职场 PUA”事件;TensorFlow 2.5.0稳定版发布极客头条 ☞ Babel 陷财务困境,负责人13万年薪遭质疑,Vue.js作者尤雨溪发文力挺 ☞ 9 岁自学编程、24 岁身价涨至数百万美元,与微软一较高低的大佬多厉害?
平台声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息存储空间服务。
- 2023年中国异型钢行业市场规模分析:同比增长229%[图] [2024-01-07]
- 乐从不锈钢新城仅用4年已成为佛山不锈钢职业领地! [2024-01-09]
- 鄂尔多斯人民政府办公室关于印发2023“鄂尔多斯杯”亚洲大洋洲软式曲棍球巡回赛暨首届AOFC沙龙锦标赛组织施行计划的告诉 [2024-01-10]
- 3月9日成都市场工角槽钢公司价格行情 [2024-01-10]
- 佛山顺德深世界才智物流工业园制作加速推动 [2024-01-10]
- 「点击转人工」特殊钢产品答疑 [2024-01-11]
- 绵阳制作!国产高温合金产品初次进入民用航空范畴 [2024-01-11]
- 2023年麻花钻十大品牌排行榜 [2024-01-11]
- 特钢冷拉职业深度研讨报告 [2024-01-12]